

苏州天剑服务工程师在国庆值班中收到用户紧急报障,生产环境中使用的3节点Nutanix集群,分布式存储服务崩溃,在ESXI中所有虚拟机显示为失效状态,存储里面查看Nutanix存储空间也显示为0B,所有虚拟机业务中断,苏州天剑服务工程在收到该用户反馈后,第一时间远程接入用户环境进行处置。

1、环境检查
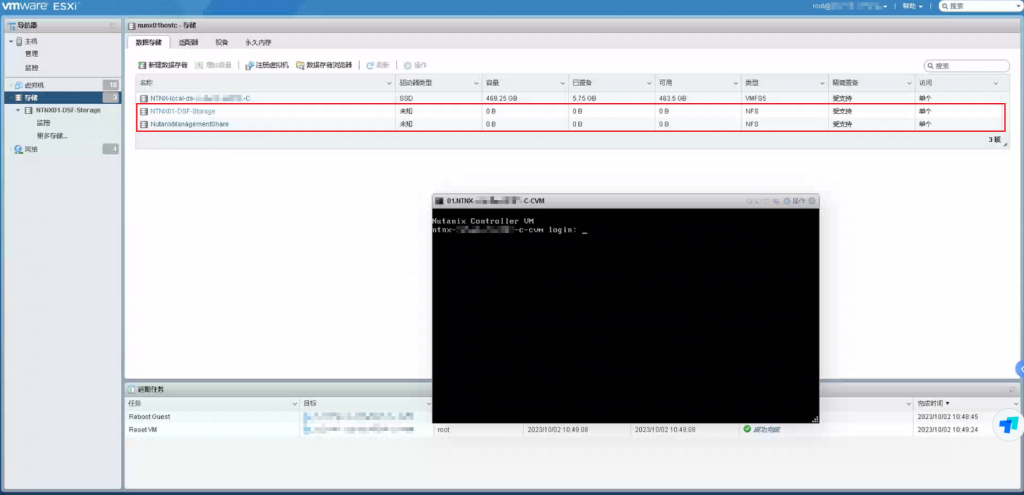
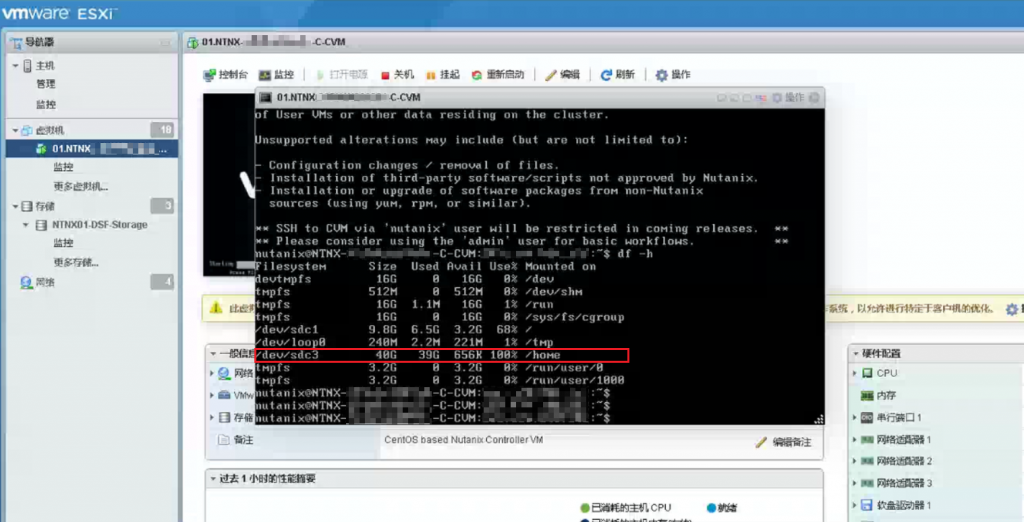
该套Nutanix超融合AOS版本为6.5 LTS与VMware融合部署,在ESXI检查各个节点上的CVM虚拟机运行正常,但是PRISM后台9440端口无法访问,通过web console进入cvm发现a、c节点的/home分区使用率极高,c节点已达到100%的使用率。
2、集群存储服务恢复
苏州天剑服务工程师初步判断为CVM/home分区磁盘满了导致服务无法启动,造成该次故障,经过对Nutanix官方kb的查阅,使用KB-1540_clean.sh的脚本进行清理并未释放/home的空间出来。
NCC-4.0.0: Health Server logs might fail to rotate and fill up /home partition
在进一步的故障诊断中,苏州天剑服务工程尝试手动释放部分/home下的日志文件,这里请注意请勿使用rm -rf命令强行删除。
将/home分区释放一部分空间出来后,服务仍未恢复,经过苏州天剑服务工程师的进一步检查确认,决定将整个集群进行重启,集群重启后,存储服务恢复,Prism Element的VIP也可以进行正常访问,但C节点仍无法访问Prism Element后台。
3、集群故障处置
在Prism Element中检查硬件状态,发现C节点无法获取信息。
在登录Prism Element后,检查告警中看到/home分区使用率过高外及集群服务崩溃的告警,告警最后出现时间与业务实际中断时间相符。
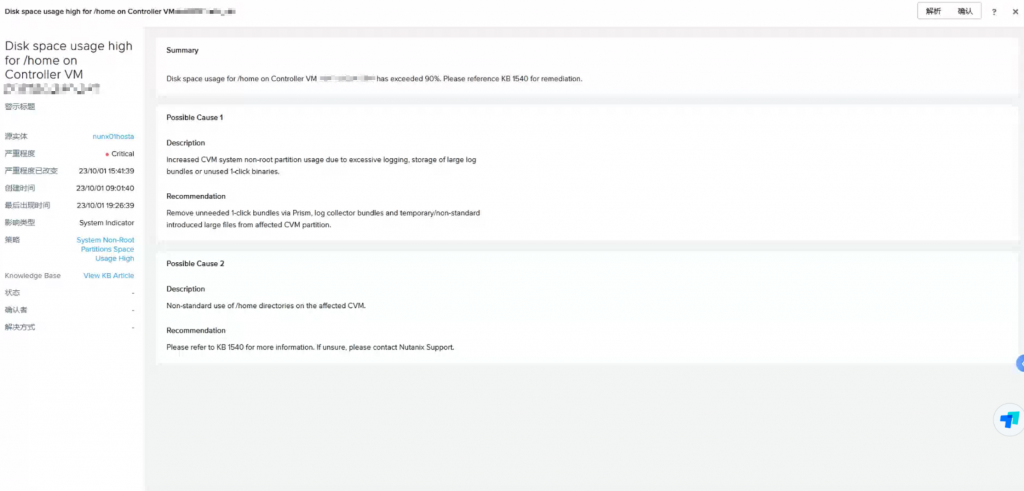
除上述告警外,有一条Disk Inode Usage High on Controller VM xxx.xxx.xxx.xxx的Critical级别告警,引起了苏州天剑服务工程师的注意。
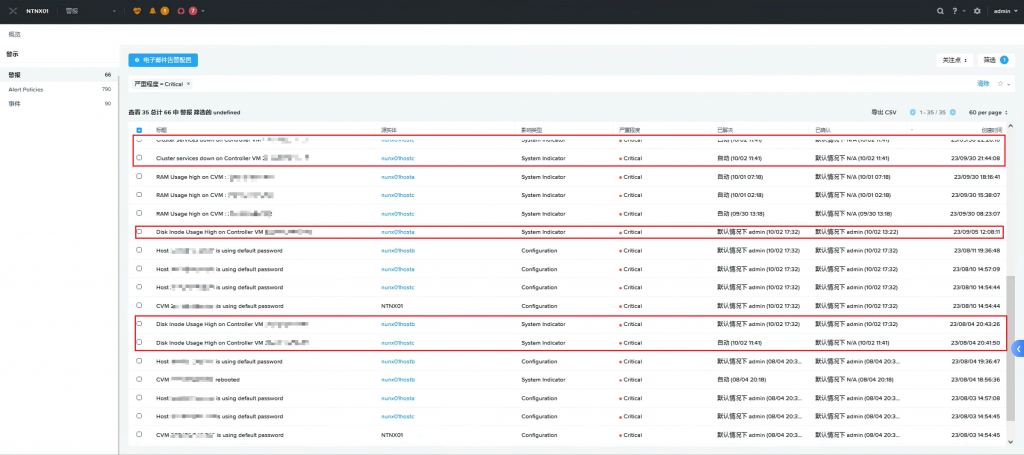
在该告警的kb帮助下,检查后发现3节点的/home下inode均已被/var/spool/postfix/maildrop写满。
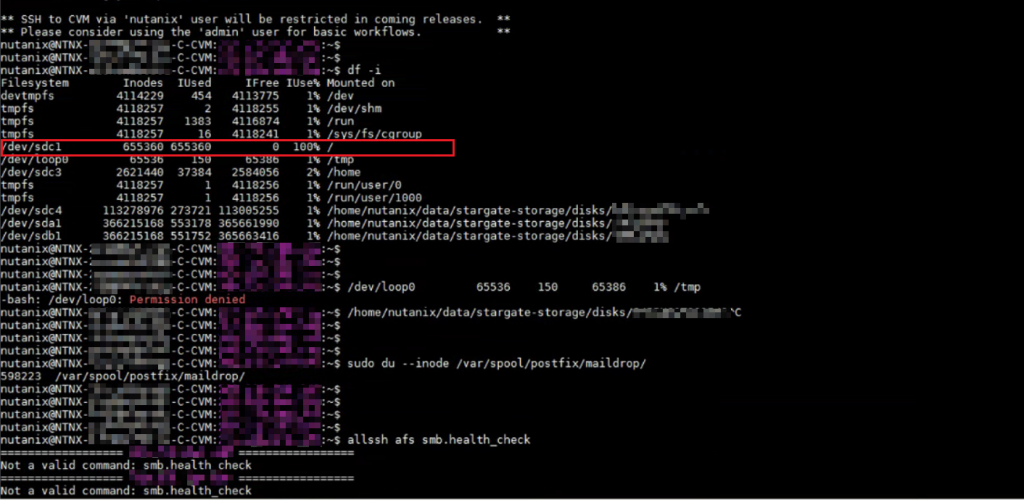
通过对inode的清理,c节点顺利上线。
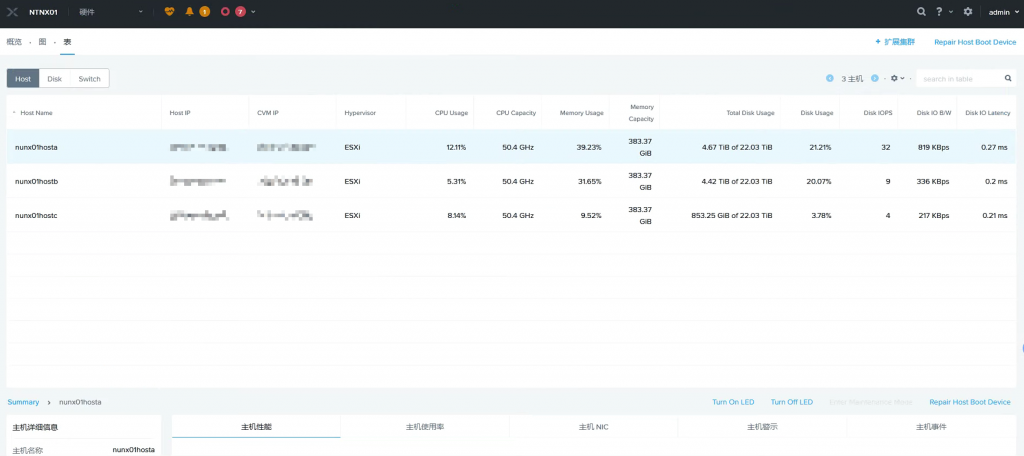
C节点顺利上线后,苏州天剑服务工程师重新执行NCC健康检查,确保集群服务的健康状态,至此故障处理排除,用户业务也完全恢复正常运行。
NCC Health Check: inode_usage_check
通过文档中的描述来看,这是个软件bug造成的问题。
Once the inode usage is bought to normal, Promptly upgrade the AOS to version 6.5.3 or a newer release. Failure to do so in a timely manner may result in cluster downtime due to inode exhuastion.
In case of Nutanix Files, Upgrade the file servers to 4.2 or a newer release.
现苏州天剑服务工程师已与用户约定Nutanix集群软件版本升级,在软件版本升级后,由于/var/spool/postfix/maildrop写满inode导致集群服务崩溃的问题将彻底解决。